
목록Note (462)
Note
www.dataedu.kr/product/adsp-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D-%EC%A4%80%EC%A0%84%EB%AC%B8%EA%B0%80-2021-%EC%99%84%EC%A0%84%EA%B0%9C%EC%A0%95%ED%8C%90-2/ ADsP 데이터분석 준전문가 2021 완전개정판 – 데이터에듀(dataedu) 저자 정보 동국대학교 산업공학과에서 데이터마이닝으로 박사 학위를 취득 후, 나이스디앤비에서 기업평가 모형 컨설팅실 실장으로 근무하며 외환은행과 신한은행 등의 국내/해외기업 신용평 www.dataedu.kr 자격증 준비를 할 때 고민을 가장 많이 했던 것이 바로 교재이다. 여기저기 후기도 찾아보고 주변 사람들에게 정보를 구해서 결정한 책이..
 4. 엑셀을 다루는 판다스
4. 엑셀을 다루는 판다스
1. 새 column 추가하기 (맨 오른쪽에 컬럼 추가) 16개 데이터를 reshape을 활용해서 4x4형태로 변경 전체 데이터 프레임에 name이라는 컬럼을 맨 오른쪽에 추가된 모습 2. 원하는 위치에 컬럼 추가하기 df.insert(위치, 추가할 컬럼, 컬럼 값, 중복여부)로 표현 원하는 위치에 지정 후 컬럼 추가 함수 insert allow_duplicates=False 원래 데이터와 중복 허용하지 않음을 뜻한다. 3. 기본 테이블을 멀티 컬럼, 인덱스로 바꾸기 df1을 인덱스로 활용해 2중 칼럼을 먼저 만든 모습 4. (이름으로) 행, 열 삭제 (이름으로) 행,열 삭제, axis=1은 열, 0은 행 5. (인덱스로) n번째 행 삭제 데이터 프레임 생성 후에 인덱스를 통해서 n번째 행을 삭제한 모습..
 pandas 10 minutes (3)
pandas 10 minutes (3)
8. Reshaping (1) stack - 데이터 쌓기 tuples와 index 생성 zip은 묶어서 재배열해주는 함수, 특수한 경우에 사용한다. 랜덤한 수를 이용해 df라는 데이터 프레임 생성 데이터 프레임 df를 4행까지 분리해서 df2에 지정해준다. 그다음 stack()을 사용하면 밑으로 데이터가 쌓인 형태를 볼 수 있다. unstack()을 사용하면 원래의 데이터 형태로 되돌릴 수 있다. 여기서, unstack(0)이나 unstack(1)을 사용하면 다양한 옵션으로 바꿀 수 있다. unstack(0)과 unstack(1)을 사용한 모습인데 원래 데이터 형태와 다른 것을 알아볼 수 있다. (2) Pivot tables(*중요!) 데이터 프레임 df 생성 pivot=기준, 기준을 잡아서 재배치한다...
 pandas 10 minutes (2)
pandas 10 minutes (2)
3. Selection (2) Selection by label : loc[] 데이터를 여러 개를 선택할 때는 리스트 형태로 입력해야 한다. 범위와 부분, 범위와 범위로 선택할 수 있다. (3) Selection by position : iloc[] (위치 기반) 데이터 프레임을 생성하고 위치 번호를 통해 특정 데이터를 가져올 수 있다. 특정 위치만 원할 경우 리스트로 작성을 하고 , 뒤에 :를 사용할 경우 모든 범위를 지정한다는 뜻이다. (4) Boolean indexing(조건에 맞는 값 가져오기) df['A']와 df 전체에서 0보다 큰 값을 찾아내는 방법이다. 0보다 작은 값을 가지는 경우는 NaN으로 표현한다. df를 df2에 복사해서 저장하고 df2에 새로운 변수 E를 추가한다. 데이터 프레임..
 pandas 10 minutes (1)
pandas 10 minutes (1)
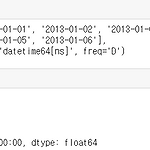
1. Object creation (1) Series 데이터 생성 (2) s에서 0번 데이터 (3) date 변수 생성 20130101부터 6일 동안의 날짜 생성. 디폴트는 freq='D' 값이며 여기서 'D'는 Day를 의미한다. (4) 데이터프레임 생성 여기서 데이터프레임은 두 가지 이상의 데이터가 결합한 형태를 말한다. 6행 4열로 랜덤한 수를 생성하고 df라는 데이터 프레임에 저장한다. index는 기준을 뜻하며, dates로 위에서 생성한 날짜 변수이다. columns는 컬럼의 이름으로 ABCD를 지정했다. 새로운 df2라는 데이터프레임 생성. 각각의 컬럼에 데이터를 지정해서 생성 후 데이터 프레임을 출력한 모습이다. 2. Viewing data (1) df.head() & df.tail() 데..