
목록유튜브 (6)
Note
 Youtube 스크립트
Youtube 스크립트
유튜브 제목 옆 줄 끝에 점 세개를 누르면 스크립트 표시가 있다. 스크립트는 유튜브에서 자동적으로 생성해주는 자막이 표시가 되어있다. 한국어 자막은 성능이 좋지 않지만 영어 자막은 꽤 잘 잡는 것으로 알고 있다. import pandas as pd import json import re import time from tqdm import tqdm import pymysql from datetime import date from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.common.ke..
# 채널 주소 입력 url = "https://www.youtube.com/channel/{}/playlists".format(channel) driver = Chrome() driver.implicitly_wait(3) driver.get(url) driver.maximize_window() body = driver.find_element_by_tag_name('body') # 페이지 밑으로 내리기 num_of_pagedowns = 5 while num_of_pagedowns: body.send_keys(Keys.PAGE_DOWN) time.sleep(2) num_of_pagedowns -= 1 html0 = driver.page_source html = bs(html0,'html.parser') # ..
# 라이브러리 호출 from requests_html import HTMLSession,AsyncHTMLSession #!pip install requests_html from bs4 import BeautifulSoup as bs # importing BeautifulSoup import nest_asyncio #!pip install nest_asyncio import pandas as pd import json import re import time from tqdm import tqdm import pymysql from sqlalchemy import create_engine pymysql.install_as_MySQLdb() import MySQLdb import numpy as np impo..
video_results = {} cnt = 0 for video_id in tqdm(array_video_id): #Video_ID 목록 if(cnt % 9 == 2): time.sleep(3) cnt += 1 result = {} video_url = "https://www.youtube.com"+video_id response = session.get(video_url,headers = headers) #URL 통신 if(response.status_code == 429): print(response) soup = bs(response.text, "html.parser") try: # 예외 발생하면 가져오지 않음 meta = soup.find_all("meta") result['video_id'] ..
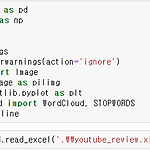 유튜브 댓글 워드 클라우드
유튜브 댓글 워드 클라우드
필요한 라이브러리를 임포트하고 앞에서 저장한 엑셀 파일을 불러온다. 데이터를 불러온 모습이다. 정규표현식을 통해서 알파벳을 제외하고 모든 문자를 제거한 모습이다. 워드 클라우드를 위해 필요 없는 칼럼을 제거하고 문자열 데이터로 변환한 모습이다. 워드 클라우드를 설치해준다. 원하는 이미지를 array의 형태로 불러온다. 불러온 이미지의 형태. 이미지는 원하는 것으로 바꿀 수 있다. 의미 없는 용어 stopword를 설정해준다. 즉, 워드 클라우드에서 제거하고 싶은 단어. 워드 클라우드를 실행하면 이러한 형태로 나오고 윈도우에 맞는 폰트를 설정해야 한다. 검색을 통해서 다른 폰트로 설정 가능하다. 이미지를 실행시키면 위에 있던 사진에 단어들이 나열된 모습을 볼 수 있다.