
Note
pandas다루기_보스톤마라톤(캐글 데이터) 본문
# 데이터 다운로드 : 캐글 -> "finishers boston marathon 2015,2016&2017"
# 셀 너비 비율 조정하는 코드
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:80% !important; }</style>"))
# 데이터 불러오기(.csv)
라이브러리 입력 후 데이터 파일(.csv) 불러오기

파일 경로 앞에 온점은 현재 경로(pwd로 확인한 위치)에 있는 폴더에서 찾겠다 라는 뜻이다.
다른 경로에 있는 파일을 불러올 경우에는 파일 경로 전체를 입력해야 한다.
1. 데이터 확인

2015년의 데이터 프레임을 확인해 본 모습.
이와 마찬가지로 2016년과 2017년도 데이터도 확인해 본다.
데이터를 전처리하는 과정에 앞서 확인해 보는 것이 좋다.

.isnull()을 사용해서 데이터 프레임에 null값이 있는지 확인한다. 있으면 True로 표시된다.

.isnull().sum()은 null값에 대한 합계이다. 해당 컬럼 안에 null값이 몇개 있는지 알 수 있다.
2. 데이터 정제(cleansing)
(1) 필요없는 컬럼 삭제

컬럼은 문자열로 입력하고 axis=1dms 컬럼을 뜻한다. 그렇게 정제한 데이터를 새로운 변수에 저장한다.

정제한 데이터에서 null값이 있는지 다시 한 번 확인하고 있는 모습이다.
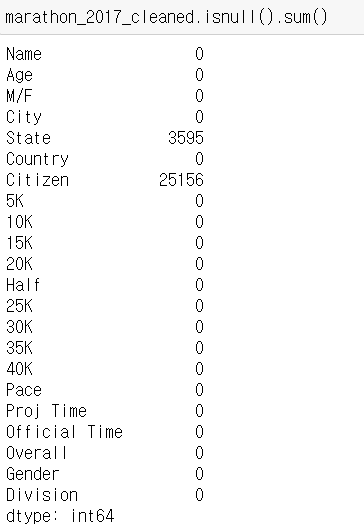
다시 한번 null값의 합계를 보면 이전보다 확실히 줄어든 것을 알 수 있다.
3. 데이터(칼럼) 추가
(1) 나이 조건을 통해서 칼럼을 추가 ( 조건 : 60세 이상은 'senior' - T/F)
조건이 Age(나이)이기 때문에 원하는 칼럼을 먼저 확인해 본다.

정제된 데이터 프레임 maraton_2017_cleaned.보고자하는 변수를 통해서 확인한다.
이 방법은 변수 이름에 띄어쓰기가 없을 때 가능하고 띄어쓰기가 있는 경우는 아래와 같이 표현한다.


맨 오른쪽에 보면 senior 변수가 True/False 형태로 추가된 것을 볼 수 있다.
(2) 'year'라는 칼럼에 2017 추가하기

나이 조건에 맞는 칼럼을 추가한 것과 같은 방법으로 year 칼럼을 추가할 수 있다.
4. 데이터 선택
Name과 Official Time 칼럼을 가져오기
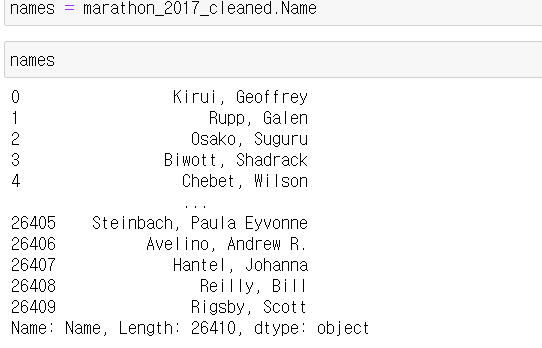

5. 조건에 맞는 데이터 선택
(1) 60세 이상인지 여부 체크하기

시니어를 결정하는 조건으로 새로운 seniors라는 변수에 저장하고 그 결과를 출력한 결과물
(2) 국적인 케냐인 사람들 데이터 가져오기
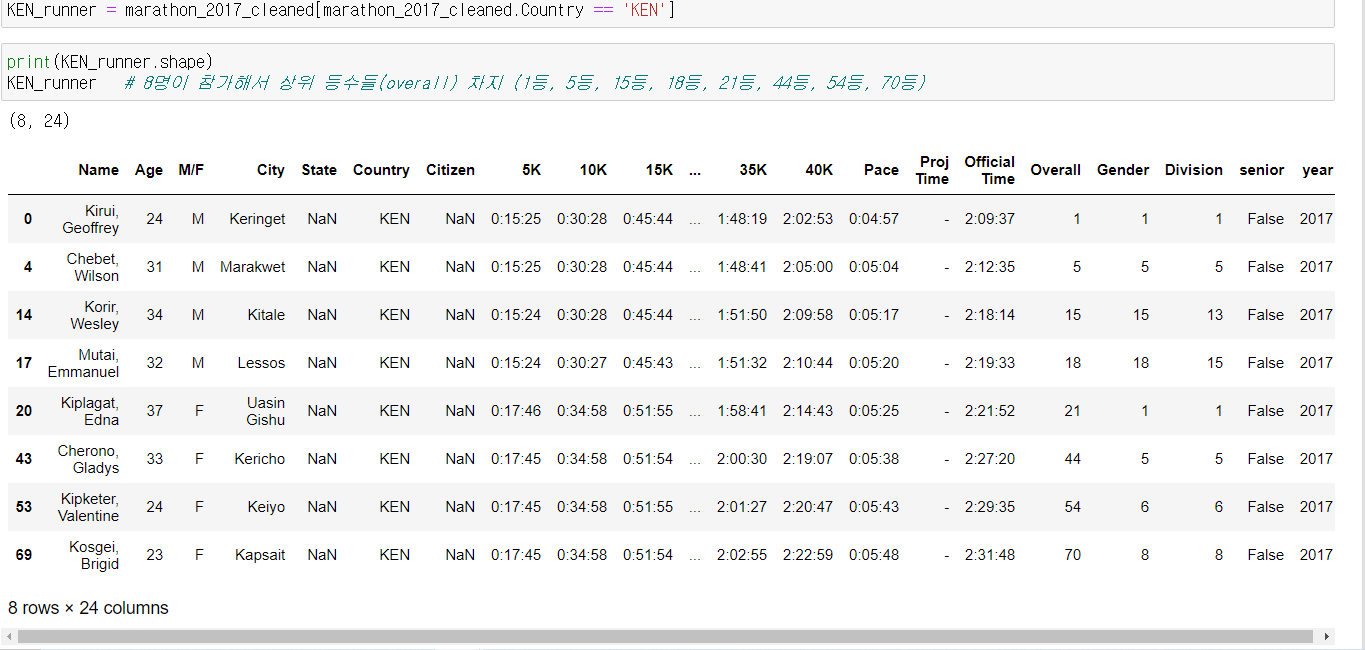
변수명 = 데이터[조건.데이터 속 변수 == '해당 조건'] 으로 표현해서 케냐 국적을 가진 사람들만 추출
8명이 참가해서 상위등수들을 차지한 것으로 보아 케냐 국적을 가진 사람들이 마라톤을 잘하는 이유에 대해 흥미를 가질 수도 있는 결과물.
6. 데이터 변환
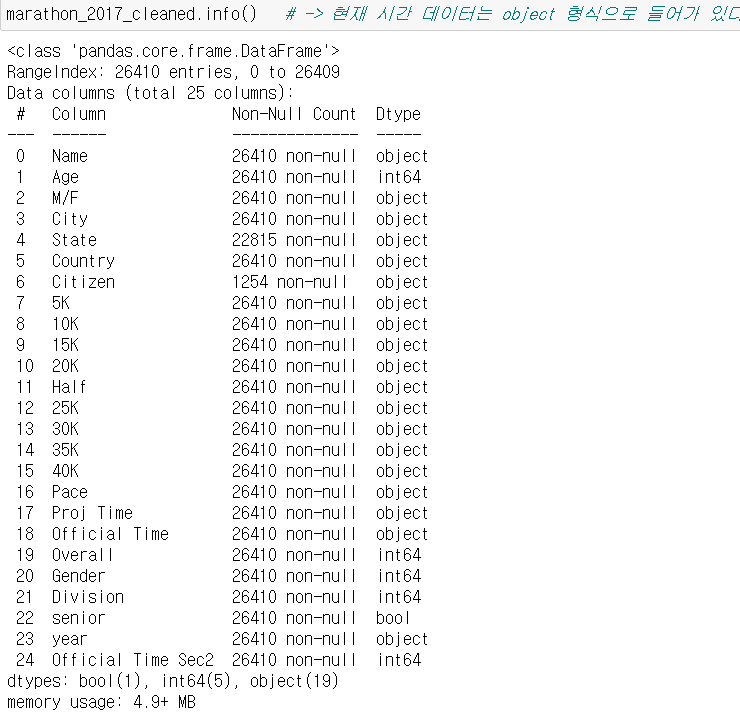
현재 시간 데이터들은 모두 object 형식으로 들어가 있어가 있기 때문에 이를 시간형태로 바꾸고 초 단위로 바꾸는 작업이 필요하다.
(1) 사용자 정의 함수 : 시간을 정제하는 함수 만들기

문자열 형태로 되어있는 시간을 int type으로 바꿔준 후 초 단위로 바꿔주는 함수.
.split('나누는 기준', n = 나누는 횟수, expand=True는 여러 컬럼)
astype(int) : 데이터 타입을 int형으로 바꿔주는 함수
데이터를 시간, 분, 초 단위로 쪼개서 각각 해당하는 숫자를 곱해서 초 단위로 변환하기 위한 작업이다.
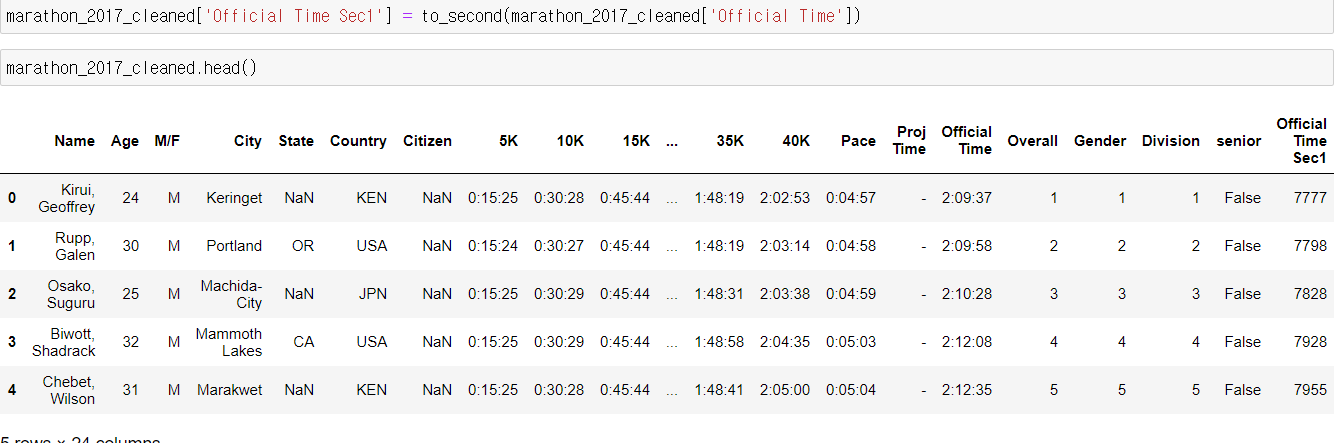
함수를 적용하고 출력한 결과물 맨 오른쪽을 보면 초 단위로 변경 된 것을 알 수 있다.
맨 위 2*3600 + 9*60 + 37 = 7200 + 540 + 37 = 7777초로 맞게 변환된 것을 볼 수 있다.
(2) pandas 내장 함수 이용 : .to_timedelta()
timedelta는 시스템에서 날짜시분초를 인식하는 시간 자료형


초 단위로 바꿔준(astype('m8[s]')) 후 int type으로 바꿔주기(astype(np.int64))
분 단위로 바꿔주는 방법(astype('m8[m]'))
사용자 지정 함수와 판다스 내장 함수 결과가 다르지 않다는 것을 확인 할 수 있다.
사용자 지정 함수도 좋지만 개인적으로 내장 함수가 있다는 것을 알면 내장함수를 활용할 것이다.
(3) sort_values를 사용해서 나이 기준으로 오름차순 정렬하기

7. 데이터 합치기 : concat

데이터 불러오기

각각의 데이터 프레임에 해당년도 변수를 추가해주고 Official Time을 기준으로 concat을 사용해서 세 데이터 프레임을 합쳐준다.

합쳐진 데이터에서 의미 없는 변수들 .drop을 사용해서 제거해준다.
데이터를 합치고 앞에서 했던 시간 데이터를 초 단위로 변경해준다.

해당 변수에 대해서 내장 함수를 이용해서 변경하고 출력 결과물을 보면 초 단위로 변경된 것을 볼 수 있다.
하지만 컴퓨터나 사람이나 반복 작업을 실행하는 것을 좋아하지 않기 때문에 for문을 활용하면 코딩이 짧아질 수 있다.
오늘 가장 어려웠던 응용이었던 for문 방법도 비슷하지만 조금씩 다른 방법이라서 비교하면서 보려고 올려보는게 좋을것 같다고 생각해서 올립니다.
응용하기에 앞서 반복하고자 하는 변수를 리스트로 만들어준다.

응용 1

응용 2

응용 3

응용 4

길던 코딩이 이렇게 짧은 한줄로 되는게 너무 신기했고 처음에는 왜 안되지 싶었는데 이미 데이터가 러닝 중이라서 0이 되버리는 오류가 있었다. 다른 방법들을 실험할 때는 데이터 불러오기부터 다시 해봤는데 모두 성공적이었다. 오늘 가장 어렵고 알고 나서 뿌듯했던 for문 응용이었는데 옆에서 도와준 수강생분들과 강사님 감사합니다.
'Machine Learning' 카테고리의 다른 글
| Numpy (넘파이) (0) | 2021.05.06 |
|---|---|
| 파이썬과 머신 러닝 (0) | 2021.05.05 |
| 4. 엑셀을 다루는 판다스 (0) | 2021.04.28 |
| pandas 10 minutes (3) (0) | 2021.04.28 |
| pandas 10 minutes (2) (0) | 2021.04.27 |



