
Note
데이터 시각화 - Scatter chart, Bubble chart (4) 본문
데이터 시각화 - Scatter chart, Bubble chart (4)
알 수 없는 사용자 2021. 5. 3. 11:521. Scatter 차트
scatter 차트는 머신러닝에서 변수 간 상관관계(correlation)를 파악하기 위해 사용한다. : 선형 회귀

데이터를 활용하려면 라이브러리 임포트와 데이터를 불러오는 것이 항상 먼저이다.

남자 참가자와 여자 참가자를 분리해서 새로운 변수로 지정해준다.

x 축에는 성별에 따른 나이로 지정을 하고 y 축에는 참가자의 공식적인 기록으로 지정해준다. y_female은 여성 참가자 나이에 따른 공식적인 기록이 정상적으로 실행되었는지 확인하는 과정이다.

그래프를 정리하면서 공통적인 것이 항상 먼저 그래프의 크기를 결정해준다. 그리고 내가 그리고자 하는 차트에 대한 기본 옵션을 설정해준다. 여기서 기본 옵션은 그래프의 모양이나 색, 투명도 등이 있다. 그 이후에는 label과 title 등의 옵션을 지정해준다.

코드를 실행하면 위와 같은 차트가 출력된다. 여성 참가자에 대한 차트는 red, 남성 참가자는 blue이다.
2. Bubble chart
버블 차트 예제는 상황이 주어진다.
상황 : 2017년 보스턴 마라톤이 2시간이 지난 시점에서 비상 상황 시 출동할 수 있는 앰뷸런스 5대를 어디에 배치시키는 것이 좋을까?
5K, 10K, 15K, 20K, 25K, 30K, 35K, 40K 8개 지점 중 어디가 적합할지 찾아보면서 사람들이 많이 모이는 지점을 찾는 방법인데 버블 차트를 통해 그것을 지도에 그려볼 수 있다.

2017년에 대한 상황이 주어졌기 때문에 2017년도 데이터만을 가져온다.

2017년도 데이터 프레임 중 필요가 없다고 판단된 칼럼을 drop을 통해 정제했다.

기존 시간 데이터를 초 단위로 변경해주는 작업이다. 이는 저번 게시글에 for문 활용을 보면 코드 길이가 짧아질 수 있다.
pd.to_timedelt() 내장 함수를 적용했고
.astype('m8[s]').astype(np.int64) -> 초단위로 바꾼 후, int 형태로 변환했다.

2시간을 기준으로 참가자들의 위치를 파악하기 위해 각 K의 지점에 대한 위도, 경도를 알아보았고 이는 나중에 지도에 지점을 찾기 위해서 활용된다.

위도 경도를 활용해서 location이라는 새로운 변수를 지정해준다.

for문과 if 함수를 통해서 참가자들의 위치를 판단한다. 여기서 사용한 iterrows()는 각각의 행을 돌아라 라는 뜻이다.

각각의 위치에 해당하는 사람들이 얼마나 있는지 숫자로 나타내 주고 그룹화를 시켜줬다.

그래프 크기를 지정해주고 차트를 적용하고 다양한 옵션을 지정해준다.
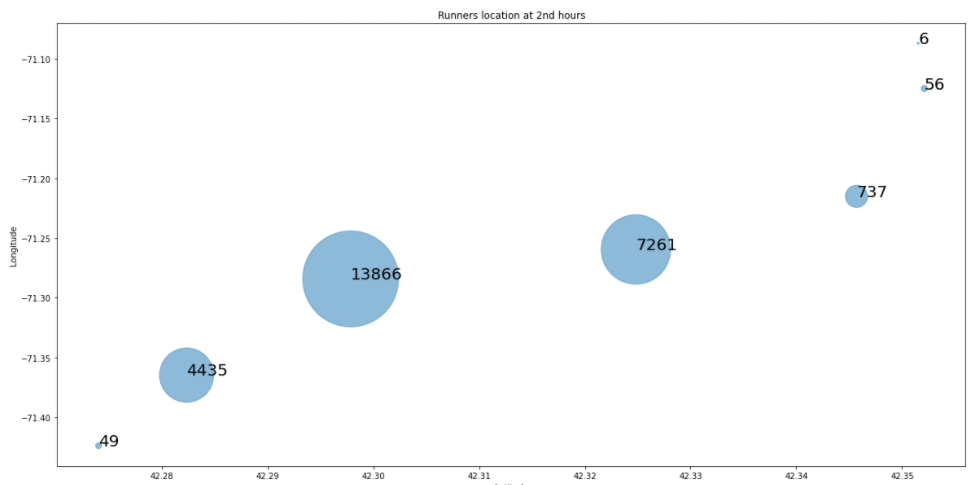
출력하면 이와 같은 그래프가 도출된다.
'Machine Learning > Data Visualization' 카테고리의 다른 글
| 데이터 시각화 - Box plot, Geo chart with Folium (6) (0) | 2021.05.03 |
|---|---|
| 데이터 시각화 - Heat map, Histogram (5) (0) | 2021.05.03 |
| 데이터 시각화 - Pie 차트, Line 차트 (3) (0) | 2021.05.02 |
| 데이터 시각화 - Dual Axis, 파레토 차트 (2) (0) | 2021.04.30 |
| 데이터 시각화 - column차트 (1) (0) | 2021.04.30 |



